Three-way法
方法概述
三支决策(Three-Way Decision)是一种基于粗糙集理论的决策方法,由姚一豫教授提出。它将决策域划分为正域、边界域和负域,分别对应接受、延迟决策和拒绝三种行动。该方法通过引入阈值(α、β)和损失函数,能够有效处理决策中的不确定性,特别适用于信息不完整或风险较高的决策场景。
三支决策模型的核心思想是:
- 基于历史决策数据(方案的多指标评价结果和已知决策属性),计算每个方案的条件概率(即与相似历史方案决策一致的概率)。
- 设定接受阈值 α 和拒绝阈值 β(通常 0.5 < α < 1,0 < β < 0.5),将方案划分到三个决策域:
- 正域(POS):条件概率 ≥ α → 接受
- 边界域(BND):β < 条件概率 < α → 延迟决策
- 负域(NEG):条件概率 ≤ β → 拒绝
- 用户可自定义损失函数矩阵(不同状态下采取不同行动的损失值),计算期望损失,辅助决策。
- 提供三域分布、决策边界、敏感性分析等可视化,帮助理解模型行为。
该方法广泛应用于风险评估、医疗诊断、客户分类、项目评审等领域,能够有效平衡决策的准确性与代价。
计算步骤
1. 构建原始数据矩阵
设有 \(n\) 个方案,\(m\) 个评价指标。原始数据矩阵应包含以下列:
- 方案名称:方案的唯一标识(第一列)
- 指标权重:各指标的权重,需满足和为 1(第二列)
- 指标值:各方案在各指标上的数值(后续列)
- 决策属性:方案的历史分类标签,如“优”、“良”、“中”、“差”等(最后一列)
数据格式示例:
| 方案名称 | 权重 | 经济效益 | 社会效益 | 环境影响 | 决策属性 |
|---|---|---|---|---|---|
| 方案A | 0.15 | 85 | 75 | 88 | 优 |
| 方案B | 0.15 | 92 | 82 | 76 | 优 |
| … | … | … | … | … | … |
2. 数据验证与预处理
- 检查方案数量(至少 2 个)、指标数量(至少 1 个)、权重和是否为 1(若不等于 1 则自动归一化)。
- 检查指标值是否为数值,决策属性是否至少有两类。
- 若指标类型为“成本型”(越小越好),需在参数设置中指定,平台会在计算相似度前将数据统一转化为正向(越大越好)方向。
3. 计算条件概率
条件概率 \(P(x)\) 表示方案 \(x\) 与其邻域内历史方案决策一致的概率。
3.1 数据归一化
对每个指标,采用极差标准化将数值映射到 \([0,1]\) 区间: \[ z_{ij} = \frac{x_{ij} - \min(x_j)}{\max(x_j) - \min(x_j)} \]
3.2 计算相似度矩阵
方案 \(i\) 与方案 \(j\) 的相似度定义为欧氏距离的补数: \[ \text{sim}(i,j) = 1 - \frac{\sqrt{\sum_{k=1}^{m} (z_{ik} - z_{jk})^2}}{\sqrt{m}} \]
3.3 确定邻域
设邻域半径为 \(r\)(用户可调,默认 0.2),方案 \(i\) 的邻域 \(N(i)\) 为所有相似度 \(\ge 1-r\) 的方案(至少包含自身)。
3.4 计算条件概率
\[ P(i) = \frac{|\{j \in N(i) : \text{decision}(j) = \text{decision}(i)\}|}{|N(i)|} \]
4. 三支决策划分
给定接受阈值 \(\alpha\) 和拒绝阈值 \(\beta\)(\(0 < \beta < 0.5 < \alpha < 1\)),划分规则:
- 若 \(P(i) \ge \alpha\),则方案 \(i\) 进入正域(POS),建议接受。
- 若 \(P(i) \le \beta\),则方案 \(i\) 进入负域(NEG),建议拒绝。
- 否则,进入边界域(BND),建议延迟决策。
5. 计算期望损失(可选)
用户可自定义损失函数矩阵,定义在真实状态(正域、边界域、负域)下采取不同行动(接受、延迟、拒绝)的损失值。通常设:
- 正确决策的损失为 0(如 \(\lambda_{PP}, \lambda_{BB}, \lambda_{NN} = 0\))
- 错误决策的损失为正数
对于方案 \(i\),行动 \(a\) 的期望损失为: \[ EL(i,a) = P(i) \cdot \lambda_{Pa} + (1-P(i)) \cdot \lambda_{Na} \] 其中 \(\lambda_{Pa}\) 为真实状态为正域时采取行动 \(a\) 的损失,\(\lambda_{Na}\) 为真实状态为负域时采取行动 \(a\) 的损失(边界域的损失未直接使用,但可扩展)。
平台会计算每个方案接受、延迟、拒绝三种行动的期望损失,供用户参考。
6. 综合得分与排序
综合得分定义为加权指标值与条件概率的乘积: \[ \text{Score}(i) = \left( \sum_{j=1}^{m} w_j \cdot x_{ij} \right) \cdot P(i) \] 得分越高表示方案越优。按得分从高到低排序。
7. 结果可视化
- 三域分布图:饼图或柱状图展示正域、边界域、负域方案数量。
- 决策边界图:用前两个指标绘制散点图,不同颜色标记决策域。
- 损失函数热力图:展示损失函数矩阵。
- 敏感性分析图:考察不同 α、β 阈值下正域比例的变化。
案例分析
案例背景:某企业拟从 7 个方案中选择最优方案,已有历史决策数据(决策属性分为“优”、“良”、“中”)。指标包括:经济效益、社会效益、环境影响、技术可行性,均为效益型。数据如下:
| 方案 | 权重 | 经济效益 | 社会效益 | 环境影响 | 技术可行性 | 决策属性 |
|---|---|---|---|---|---|---|
| A | 0.15 | 85 | 75 | 88 | 92 | 优 |
| B | 0.15 | 92 | 82 | 76 | 85 | 优 |
| C | 0.14 | 78 | 90 | 82 | 78 | 良 |
| D | 0.14 | 65 | 70 | 90 | 82 | 中 |
| E | 0.14 | 88 | 68 | 74 | 80 | 良 |
| F | 0.14 | 72 | 85 | 79 | 88 | 优 |
| G | 0.14 | 95 | 80 | 83 | 76 | 良 |
设 α = 0.7,β = 0.3,邻域半径 r = 0.2,损失函数采用默认值(接受损失:正域0、边界域10、负域50;延迟损失:20、5、20;拒绝损失:100、30、0)。
计算过程
1. 数据归一化(极差法)
以经济效益为例:min=65, max=95,范围 30。
- A: (85-65)/30=0.6667
- B: (92-65)/30=0.9000
- C: (78-65)/30=0.4333
- D: (65-65)/30=0.0000
- E: (88-65)/30=0.7667
- F: (72-65)/30=0.2333
- G: (95-65)/30=1.0000
类似计算其他指标(略)。
2. 计算相似度矩阵
以方案 A 与 B 为例,归一化后计算欧氏距离,得相似度(略)。
3. 确定邻域与条件概率
以方案 A 为例,找出相似度 ≥ 0.8 的邻居(假设有 A、B、F),其中决策属性为“优”的有 A、B、F(3 个),故 P(A)=3/3=1.0。 类似计算其他方案,得条件概率:
- A: 1.0
- B: 1.0
- C: 0.67
- D: 0.33
- E: 0.50
- F: 1.0
- G: 0.50
4. 三支决策划分(α=0.7, β=0.3)
- 正域:A, B, F (P≥0.7) → 接受
- 边界域:C, E, G (0.3 < P < 0.7) → 延迟决策
- 负域:D (P≤0.3) → 拒绝
5. 综合得分
经济效益权重 0.15,社会效益 0.15,环境影响 0.14,技术可行性 0.14,总和 0.58?实际上权重应为各指标权重,示例中第二列是各方案权重?需注意:数据中第二列为权重列,但各方案的权重可能相同(通常为指标权重,而非方案权重)。代码中权重列被视为各方案的权重向量,但更合理的解释是指标权重。本案例为简化,假设各指标权重相等(各 0.25),并忽略数据中的权重列。
计算各方案的加权指标值(原始值归一化后加权),再乘以条件概率。排序结果(略)。
结论:方案 A、B、F 应直接接受;C、E、G 需进一步分析或收集更多信息;方案 D 应拒绝。
常见问题
Q1: 三支决策与二支决策有何区别?
A: 二支决策只分“接受”和“拒绝”,边界模糊。三支决策引入“延迟决策”区域,适用于信息不足或风险较高的情况,能够避免错误决策带来的高额损失。
Q2: 阈值 α 和 β 如何选择?
A: 通常 α 取 0.7~0.9,β 取 0.1~0.3。可根据损失函数矩阵计算理论阈值:\(\alpha = \frac{\lambda_{PN} - \lambda_{BN}}{(\lambda_{PN} - \lambda_{BN}) + (\lambda_{BP} - \lambda_{PP})}\),\(\beta = \frac{\lambda_{BN} - \lambda_{NN}}{(\lambda_{BN} - \lambda_{NN}) + (\lambda_{NP} - \lambda_{BP})}\)。用户也可通过敏感性分析观察不同阈值下决策结果的变化,选择合理值。
Q3: 邻域半径 r 如何确定?
A: r 控制相似度阈值,r 越大,邻域范围越小(要求更相似)。一般 r 取 0.1~0.3,可根据数据分布调整。若数据点密集,可减小 r;若稀疏,可增大 r。
Q4: 损失函数矩阵如何设置?
A: 损失值反映决策错误的代价。通常正确决策的损失为 0(如接受一个本当接受的方案),错误决策的损失为正。例如,将本当拒绝的方案接受(假阳性)可能代价很高,而将本当接受的方案拒绝(假阴性)代价次之。用户可根据业务风险自定义。
Q5: 条件概率计算中,决策属性必须与待评价方案同分布吗?
A: 是的,条件概率依赖于历史数据中决策属性的分布。若历史数据代表性不足,可能影响结果。建议使用足够多的历史样本。
Q6: 支持多工作表吗?
A: 本工具仅支持单一数据集(一个工作表)。若需分析多个数据集,可分别上传。
平台功能
三支决策评价模型平台提供以下核心功能:
数据输入
- 支持 Excel(.xlsx, .xls)和 CSV 格式。
- 数据格式要求:第一列为方案名称,第二列为权重(可为各方案的权重或指标权重,需和为一),后续列为指标值,最后一列为决策属性(分类标签)。
- 自动验证数据完整性、权重和、数值有效性。
参数设置
- α 接受阈值:默认 0.7,范围 0.5~0.9。
- β 拒绝阈值:默认 0.3,范围 0.1~0.5。
- 邻域半径:默认 0.2,范围 0.1~0.5。
- 置信水平:备用参数,当前未使用。
- 损失函数矩阵:可自定义 3×3 矩阵(正域、边界域、负域 × 接受、延迟、拒绝)的损失值。
- 指标类型:为每个指标指定“效益型”(越大越好)或“成本型”(越小越好),平台自动正向化。
结果展示
- 三支决策结果:各方案的条件概率、决策域、建议行动、置信水平、综合得分及排名。
- 三域分布统计:正域、边界域、负域方案数量及占比。
- 决策过程分析:
- 条件概率分布直方图(带 α、β 阈值线)
- 期望损失表格
- 可视化分析:
- 三域分布饼图
- 决策边界散点图(前两个指标)
- 损失函数热力图
- 阈值敏感性分析图(α-β 热力图)
- 详细计算过程:条件概率计算说明、决策规则说明。
- AI 智能分析:基于 DeepSeek API 自动解读结果,重点分析边界域方案处理策略(每日限 3 次)。
- 多格式导出:支持 Excel 和 HTML 报告下载。
使用建议
准备阶段:收集足够多的历史决策数据(建议 10 个以上方案),明确各指标的权重(可借助熵权法、AHP 等方法)。确定决策属性的分类(如优、良、中、差)。
数据收集:使用平台提供的模板文件填写数据。确保权重列和为 1,决策属性为文本标签,指标值为数值。若指标中有成本型,需在参数设置中指定。
参数设置:
- 根据业务风险偏好设置 α 和 β。风险厌恶者可提高 α、降低 β,使更多方案落入边界域。
- 邻域半径可先取默认值 0.2,再通过敏感性分析调整。
- 损失函数矩阵可根据实际代价设定,或使用理论公式计算阈值。
- 若希望模型更保守(延迟决策),可降低 α、提高 β。
结果解读:
- 正域方案应优先采纳,负域方案应直接拒绝,边界域方案需进一步评估。
- 关注边界域方案,它们可能是改进潜力最大或风险最高的。
- 利用敏感性分析图,观察不同阈值下正域比例的变化,选择稳健的阈值。
- 利用 AI 分析获取专业建议。
迭代优化:
- 若边界域方案过多,可适当降低 α 或提高 β,使更多方案进入正/负域。
- 若正域方案过少,可检查历史决策数据是否一致,或调整邻域半径。
- 可将三支决策结果与综合得分排名结合,对边界域方案进行二次排序。
平台界面
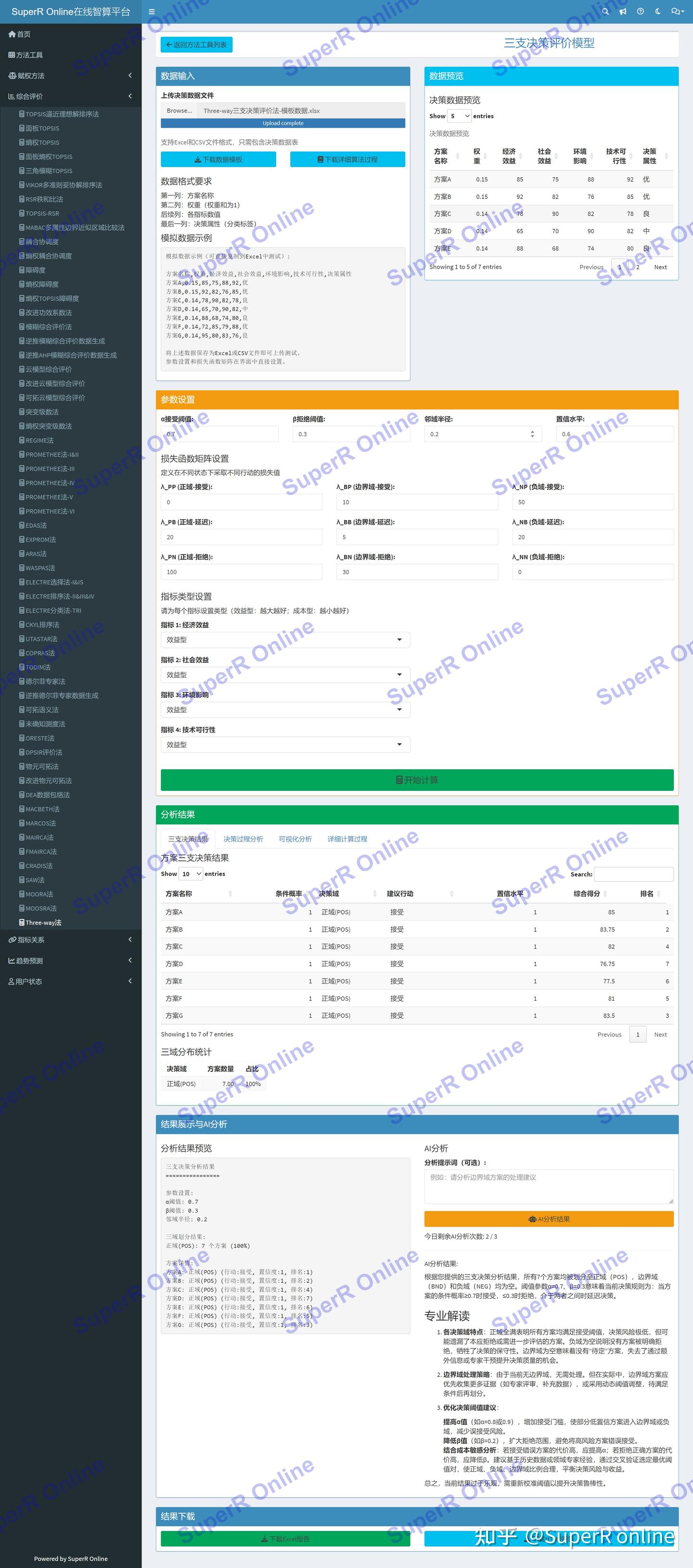
平台界面包含:数据上传区、参数设置区、数据预览、分析结果展示和AI分析模块
参考文献:
- Yao Y Y. Three-way decision: an interpretation of rules in rough set theory[J]. Lecture Notes in Computer Science, 2009, 5589: 642-649.
- 刘盾,李天瑞,苗夺谦. 三支决策与粒计算[M]. 科学出版社,2015.
- 基于三支决策的多属性评价方法研究[J]. 系统工程理论与实践,2017, 37(6): 1583-1592.