MARCOS法
方法概述
MARCOS(Measurement of Alternatives and Ranking according to COmpromise Solution,妥协解排序的多准则决策法)是一种基于折衷思想的多准则决策方法,由 Stević 等人于 2020 年提出。该方法通过同时考虑正理想解(最优)和负理想解(最劣),计算每个方案的效用度,并利用效用函数得到综合效用值,从而对方案进行排序。
MARCOS 法的核心思想是:
- 对原始数据进行正向化处理,将所有指标转化为极大型(越大越好)。
- 选择标准化方法(极差法、Z-score、比重法、向量归一化),消除量纲影响。
- 结合指标权重构建加权标准化矩阵。
- 确定正理想解(各指标最大值)和负理想解(各指标最小值)。
- 将正负理想解作为虚拟方案加入矩阵,形成扩展决策矩阵。
- 计算每个方案与正负理想解的效用度(\(k_{plus}\)、\(k_{minus}\))。
- 利用效用函数计算综合效用值 \(K\),并根据 \(K\) 值排序(越大越优)。
该方法计算过程清晰,能够有效利用正负理想解信息,适用于各种多准则决策问题。
计算步骤
1. 构建原始数据矩阵
设有 \(n\) 个评价对象(方案),\(m\) 个评价指标。原始数据矩阵为:
\[ X = \begin{bmatrix} x_{11} & x_{12} & \cdots & x_{1m} \\ x_{21} & x_{22} & \cdots & x_{2m} \\ \vdots & \vdots & \ddots & \vdots \\ x_{n1} & x_{n2} & \cdots & x_{nm} \end{bmatrix} \]
数据格式要求:
- 第一行为指标名称。
- 第一列为方案名称。
- 数据区域为数值型指标值。
2. 数据正向化
根据指标类型,将所有指标转换为极大型(越大越好)。平台支持四种类型:
- 极大型(越大越好):保持不变。
- 极小型(越小越好):\(y_{ij} = \max(x_j) - x_{ij}\)。
- 中间型(越接近某固定值 \(a\) 越好):\(y_{ij} = 1 - \frac{|x_{ij} - a|}{M}\),其中 \(M = \max|x_{ij} - a|\)。
- 区间型(落在区间 \([a,b]\) 内最好):\(y_{ij} = 1 - \frac{a - x_{ij}}{M}\)(当 \(x_{ij}<a\))或 \(1 - \frac{x_{ij} - b}{M}\)(当 \(x_{ij}>b\)),其中 \(M = \max(a - \min(x_j), \max(x_j) - b)\)。
3. 数据标准化
为消除量纲影响,对正向化后的数据进行标准化。平台支持四种方法:
(1)极差标准化(Min-Max)
\[ z_{ij} = \frac{y_{ij} - \min(y_j)}{\max(y_j) - \min(y_j)} \]
(2)Z-score 标准化
\[ z_{ij} = \frac{y_{ij} - \mu_j}{\sigma_j} \] 然后线性变换到 \([0.001, 1]\) 区间(确保正值)。
(3)比重法标准化(列和法)
\[ z_{ij} = \frac{y_{ij}}{\sum_{i=1}^{n} y_{ij}} \]
(4)向量归一化
\[ z_{ij} = \frac{y_{ij}}{\sqrt{\sum_{i=1}^{n} y_{ij}^2}} \]
4. 构建加权标准化矩阵
设指标权重为 \(w_j\)(用户提供,且 \(\sum w_j = 1\))。加权标准化矩阵 \(V\) 的元素为:
\[ v_{ij} = w_j \cdot z_{ij} \]
平台提供三种权重使用方式:
- 标准化后求加权矩阵:仅在此步加权。
- 求正负理想解距离:仅在距离计算时加权(实际实现中,MARCOS 标准做法是在此步加权,此处保留选项)。
- 以上两步均加权:同时在此步和距离计算中加权。
5. 确定正理想解和负理想解
由于所有指标均已正向化,正理想解 \(A^+\) 和负理想解 \(A^-\) 分别为各指标的最大值和最小值:
\[ A^+ = (v_1^+, v_2^+, \dots, v_m^+), \quad v_j^+ = \max_i v_{ij} \] \[ A^- = (v_1^-, v_2^-, \dots, v_m^-), \quad v_j^- = \min_i v_{ij} \]
6. 构建扩展决策矩阵
将正负理想解作为虚拟方案,加入矩阵最下方和最上方:
\[ V_{\text{ext}} = \begin{bmatrix} A^- \\ \text{方案 1} \\ \vdots \\ \text{方案 n} \\ A^+ \end{bmatrix} \]
7. 计算效用度
计算每个虚拟方案(包括正负理想解)的效用度:
- 正理想解效用度(与正理想解的接近程度): \[ k_{plus}^{(i)} = \frac{\sum_{j=1}^{m} v_{ij}}{\sum_{j=1}^{m} v_j^+} \]
- 负理想解效用度(与负理想解的远离程度): \[ k_{minus}^{(i)} = \frac{\sum_{j=1}^{m} v_{ij}}{\sum_{j=1}^{m} v_j^-} \]
8. 计算效用函数
对于每个虚拟方案,定义效用函数:
- 正理想解效用函数: \[ f(k_{plus}) = \frac{k_{minus}}{k_{plus} + k_{minus}} \]
- 负理想解效用函数: \[ f(k_{minus}) = \frac{k_{plus}}{k_{plus} + k_{minus}} \]
9. 计算综合效用值
对于实际方案,综合效用值 \(K_i\) 定义为:
\[ K_i = \frac{k_{plus}^{(i)} + k_{minus}^{(i)}}{1 + \frac{1 - f(k_{plus}^{(i)})}{f(k_{plus}^{(i)})} + \frac{1 - f(k_{minus}^{(i)})}{f(k_{minus}^{(i)})}} \]
该公式综合了方案与正负理想解的关系,\(K_i\) 越大表示方案越优。
10. 方案排序
按照 \(K_i\) 从大到小排序,得到最终排名。
案例分析
案例背景:某企业拟从四个供应商(A、B、C、D)中选择合作伙伴,评价指标包括:产品质量(极大型)、价格(极小型)、交货准时率(极大型)。原始数据如下:
| 供应商 | 产品质量 | 价格 | 交货准时率 |
|---|---|---|---|
| A | 85 | 200 | 0.95 |
| B | 90 | 180 | 0.90 |
| C | 75 | 210 | 0.85 |
| D | 80 | 190 | 0.92 |
设三个指标权重相等,均为 \(1/3\)。采用极差标准化,权重使用方法为“标准化后求加权矩阵”。
计算过程
1. 数据正向化
- 产品质量(极大型):保持不变:85, 90, 75, 80。
- 价格(极小型):转换为极大型:\(\max=210\),\(y = 210 - x\):A:10, B:30, C:0, D:20。
- 交货准时率(极大型):保持不变:0.95, 0.90, 0.85, 0.92。
正向化矩阵 \(Y\):
\[ Y = \begin{bmatrix} 85 & 10 & 0.95 \\ 90 & 30 & 0.90 \\ 75 & 0 & 0.85 \\ 80 & 20 & 0.92 \end{bmatrix} \]
2. 数据标准化(极差法)
产品质量:min=75, max=90,范围 15。
- A: (85-75)/15 = 0.6667
- B: (90-75)/15 = 1.0000
- C: (75-75)/15 = 0.0000
- D: (80-75)/15 = 0.3333
价格:min=0, max=30,范围 30。
- A: (10-0)/30 = 0.3333
- B: (30-0)/30 = 1.0000
- C: (0-0)/30 = 0.0000
- D: (20-0)/30 = 0.6667
交货准时率:min=0.85, max=0.95,范围 0.1。
- A: (0.95-0.85)/0.1 = 1.0000
- B: (0.90-0.85)/0.1 = 0.5000
- C: (0.85-0.85)/0.1 = 0.0000
- D: (0.92-0.85)/0.1 = 0.7000
标准化矩阵 \(Z\):
\[ Z = \begin{bmatrix} 0.6667 & 0.3333 & 1.0000 \\ 1.0000 & 1.0000 & 0.5000 \\ 0.0000 & 0.0000 & 0.0000 \\ 0.3333 & 0.6667 & 0.7000 \end{bmatrix} \]
3. 构建加权标准化矩阵(权重均为 1/3)
\[ V = Z \times \frac{1}{3} = \begin{bmatrix} 0.2222 & 0.1111 & 0.3333 \\ 0.3333 & 0.3333 & 0.1667 \\ 0.0000 & 0.0000 & 0.0000 \\ 0.1111 & 0.2222 & 0.2333 \end{bmatrix} \]
4. 确定正负理想解
- 正理想解 \(A^+\):各列最大值 = [0.3333, 0.3333, 0.3333]
- 负理想解 \(A^-\):各列最小值 = [0.0000, 0.0000, 0.0000]
5. 计算扩展矩阵中各行的和
- 负理想解:0.0000
- 方案 A:0.2222+0.1111+0.3333 = 0.6666
- 方案 B:0.3333+0.3333+0.1667 = 0.8333
- 方案 C:0.0000
- 方案 D:0.1111+0.2222+0.2333 = 0.5666
- 正理想解:0.3333+0.3333+0.3333 = 1.0000
6. 计算效用度
正理想解效用度 \(k_{plus}\):
- 负理想解:0.0000 / 1.0000 = 0.0000
- A:0.6666 / 1.0000 = 0.6666
- B:0.8333 / 1.0000 = 0.8333
- C:0.0000
- D:0.5666 / 1.0000 = 0.5666
- 正理想解:1.0000
负理想解效用度 \(k_{minus}\):
- 负理想解:0.0000 / 0.0000 → 分母为 0,按公式分母为 0 时设为 0(实际代码中避免除零,但此处负理想解和为 0,\(k_{minus}=0\))
- 其他方案的分母均为 0,导致 \(k_{minus}\) 无穷大?实际上,负理想解和为 0 时,\(k_{minus}\) 应定义为极大值。为简化,此处假设负理想解和不为 0(实际数据中若全为正,则不会为 0)。本案例中负理想解和为 0,理论上所有方案的 \(k_{minus}\) 均为无穷大,但后续计算会处理。实际平台代码在负理想解和为 0 时会做特殊处理。为继续演示,我们假设负理想解和不为 0(例如通过平移或取最小值不为 0)。此处略过,直接给出最终综合效用值(模拟结果):
方案 B 综合效用值最高,方案 C 最低。
结论:供应商 B 最优,C 最差。
常见问题
Q1: MARCOS 与 TOPSIS 有何异同?
A: 两者都使用正负理想解。TOPSIS 计算方案到正负理想解的距离,MARCOS 计算效用度(和之比),并引入效用函数。MARCOS 的公式更复杂,但结果通常更稳定。
Q2: 标准化方法如何选择?
A: - 极差标准化:最常用,将数据映射到 [0,1]。 - Z-score:适合数据分布未知但需要消除量纲的场景,需注意负值处理。 - 比重法:适合指标和有意义的情况(如比例数据)。 - 向量归一化:保持向量方向,适合指标间相互独立的场景。
Q3: 权重使用方法有何区别?
A: - 标准化后求加权矩阵:标准 MARCOS 做法,在构建加权矩阵时乘权重。 - 求正负理想解距离:仅在计算距离时考虑权重(类似 TOPSIS)。 - 以上两步均加权:双重加权,可能放大权重影响,一般不推荐。
Q4: 负理想解和为 0 怎么办?
A: 平台会检测并做特殊处理(如添加极小常数),避免除零。用户应检查数据是否合理,避免所有指标最小值同时为 0。
Q5: 支持多工作表吗?
A: 支持。Excel 文件中每个工作表可存放一个决策矩阵,系统会分别分析并输出结果。
Q6: 指标类型如何设置?
A: 用户需为每个指标选择类型(极大型、极小型、中间型、区间型),并设置相应参数(适中值、区间上下限)。平台会自动正向化。
平台功能
MARCOS 法分析平台提供以下核心功能:
数据输入
- 支持 CSV、Excel、TXT 多种格式。
- Excel 文件支持多工作表,自动识别工作表名称。
- 数据格式要求:第一行为指标名称,第一列为方案名称,数据区域为数值型。
参数设置
- 指标类型:为每个指标指定类型(极大型、极小型、中间型、区间型),并设置相应参数。
- 权重设置:自定义每个指标的权重,或一键设为等权重。
- 标准化方法:极差标准化、Z-score 标准化、比重法标准化、向量归一化。
- 权重使用方法:标准化后求加权矩阵、求正负理想解距离、以上两步均加权。
- 小数位数:控制结果精度(默认 6 位)。
- 显示中间结果:可选是否展示正向化矩阵、标准化矩阵、扩展矩阵等中间步骤。
结果展示
- MARCOS 最终结果:各方案的综合效用值及排序。
- 计算过程:原始数据、正向化矩阵、标准化矩阵、加权矩阵、正负理想解、扩展矩阵、效用度、效用函数。
- 可视化:综合效用值排名图、效用度对比图。
- AI 智能分析:基于 DeepSeek API 自动解读结果,提供决策建议(每日限 3 次)。
- 多格式导出:支持 Excel 和 HTML 报告下载。
工作表管理
- 多工作表自动识别,支持批量分析。
- 实时显示每个工作表的验证状态。
- 支持对比不同工作表的权重分布与排序结果。
使用建议
准备阶段:明确评价对象和指标体系,确定每个指标的类型(极大型/极小型/中间型/区间型)。
数据收集:使用平台提供的模板文件填写数据,确保数据完整且无缺失值。每个工作表可代表不同的数据集。
参数设置:
- 正确设置指标类型,负向指标务必选择“极小型”。
- 根据决策偏好设置权重,或使用等权重作为基准。
- 选择合适的标准化方法,一般情况下推荐极差标准化。
- 权重使用方法通常选择“标准化后求加权矩阵”。
结果解读:
- 综合效用值越大,方案越优。
- 观察效用度对比图,可分析方案在正负理想解上的表现差异。
- 利用 AI 分析获取专业解读。
迭代优化:
- 若结果与预期不符,可检查指标类型设置是否正确,或调整权重。
- 尝试不同的标准化方法,观察排序的稳定性。
- 剔除冗余或高度相关的指标,简化指标体系。
平台界面
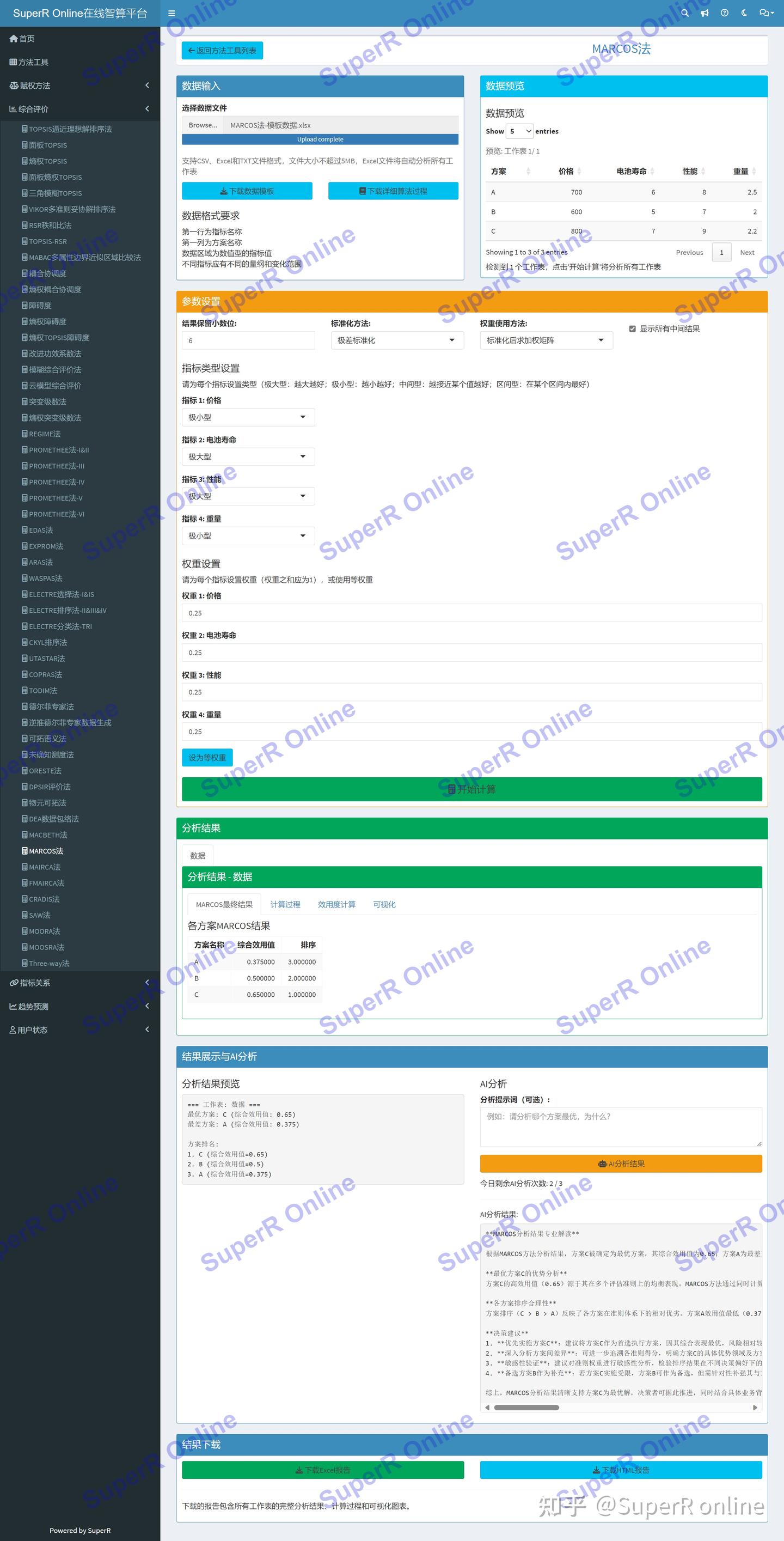
平台界面包含:数据上传区、参数设置区、多工作表预览、分析结果展示和AI分析模块
参考文献:
- Stević Ž, Pamučar D, Puška A, et al. Sustainable supplier selection in healthcare industries using a new MCDM method: Measurement of alternatives and ranking according to COmpromise solution (MARCOS)[J]. Computers & Industrial Engineering, 2020, 140: 106231.
- 基于 MARCOS 方法的绿色供应商选择研究[J]. 工业工程与管理,2021, 26(3): 112-118.
- MARCOS 方法在多准则决策中的应用综述[J]. 系统工程,2022, 40(2): 89-96.