GM(1,1)灰色预测
方法概述
GM(1,1) 灰色预测是灰色系统理论中最基础、最常用的预测模型,由邓聚龙教授于 1982 年提出。该模型通过对原始数据序列进行一次累加生成(1-AGO),挖掘系统的指数增长规律,建立一阶单变量微分方程,从而对未来发展趋势进行预测。
GM(1,1) 灰色预测的核心思想是:
- 将原始非负时间序列通过一次累加生成,弱化随机性,增强规律性。
- 建立一阶线性微分方程模型,求解发展系数 (a) 和灰色作用量 (b)。
- 利用时间响应函数计算拟合值,并通过累减还原得到预测值。
- 提供多种检验指标:级比检验、相对误差检验、级比偏差检验、后验差检验,综合评估模型精度。
- 支持数据平移处理(当原始数据不满足级比条件或包含非正数时自动平移)。
- 可视化展示历史数据、拟合值与预测值的对比图。
该方法适用于小样本(通常 4 个以上数据点)、信息不完全、数据呈现指数趋势的短期预测问题,广泛应用于经济、农业、环境、管理等领域。
计算步骤
1. 构建原始数据序列
设有原始非负时间序列:
\[ X^{(0)} = (x^{(0)}(1), x^{(0)}(2), \dots, x^{(0)}(n)) \]
其中 (n) 为数据个数,通常要求 (n )。第一列为时间标识,第二列为观测值。
2. 级比检验与数据平移
计算级比(光滑比):
\[ \lambda(k) = \frac{x^{(0)}(k-1)}{x^{(0)}(k)}, \quad k=2,3,\dots,n \]
级比的可容覆盖区间为:
\[ \Theta = \left( e^{-\frac{2}{n+1}}, e^{\frac{2}{n+1}} \right) \]
若所有 ((k)) 均落在 () 内,则原始序列可直接建模;否则需对数据进行平移变换:
\[ y^{(0)}(k) = x^{(0)}(k) + c \]
其中 (c) 取适当正数使得新序列的级比满足要求。平移值会在结果中给出。
3. 一次累加生成(1-AGO)
对原始序列(或平移后序列)进行一次累加,得到累加序列:
\[ X^{(1)}(k) = \sum_{i=1}^{k} x^{(0)}(i), \quad k=1,2,\dots,n \]
累加后的序列通常呈现指数增长趋势。
4. 建立灰微分方程
构造数据矩阵 (B) 和常数项向量 (Y):
\[ B = \begin{bmatrix} -\frac{1}{2}[x^{(1)}(1)+x^{(1)}(2)] & 1 \\ -\frac{1}{2}[x^{(1)}(2)+x^{(1)}(3)] & 1 \\ \vdots & \vdots \\ -\frac{1}{2}[x^{(1)}(n-1)+x^{(1)}(n)] & 1 \end{bmatrix}, \quad Y = \begin{bmatrix} x^{(0)}(2) \\ x^{(0)}(3) \\ \vdots \\ x^{(0)}(n) \end{bmatrix} \]
灰微分方程为:
\[ x^{(0)}(k) + a z^{(1)}(k) = b, \quad k=2,3,\dots,n \]
其中 (z^{(1)}(k) = [x{(1)}(k-1)+x{(1)}(k)]) 为背景值。
5. 求解参数
利用最小二乘法估计参数 () 和 ():
\[ \begin{bmatrix} \hat{a} \\ \hat{b} \end{bmatrix} = (B^T B)^{-1} B^T Y \]
- (a) 称为发展系数,反映系统的发展态势:(a<0) 表示增长,(a>0) 表示衰减,(|a|) 越小模型越稳定。
- (b) 称为灰色作用量,反映外部因素对系统的影响。
6. 时间响应函数与拟合值
时间响应函数(累加序列的预测公式)为:
\[ \hat{x}^{(1)}(k) = \left( x^{(0)}(1) - \frac{b}{a} \right) e^{-a(k-1)} + \frac{b}{a}, \quad k=1,2,\dots,n, n+1, \dots \]
累减还原得到原始序列的拟合值((k=1) 时取原始值):
\[ \hat{x}^{(0)}(k) = \hat{x}^{(1)}(k) - \hat{x}^{(1)}(k-1), \quad k=2,3,\dots,n \]
7. 外推预测
对未来 (m) 个时刻((k=n+1, n+2, , n+m))同样利用时间响应函数计算累加预测值,再累减还原得到预测值。
若建模前进行了平移,则最终预测值需减去平移量 (c)。
8. 模型检验
(1)级比检验
验证原始序列是否满足建模条件,给出级比区间和是否通过的结论。
(2)相对误差检验
计算每个点的相对误差:
\[ \varepsilon(k) = \left| \frac{x^{(0)}(k) - \hat{x}^{(0)}(k)}{x^{(0)}(k)} \right| \times 100\% \]
平均相对误差 ({}) 用于评价模型精度:
| 等级 | 平均相对误差 |
|---|---|
| 优 | < 1% |
| 良 | < 5% |
| 合格 | < 10% |
| 不合格 | ≥ 10% |
(3)级比偏差检验
计算级比偏差:
\[ \rho(k) = \left| 1 - \frac{1-0.5a}{1+0.5a} \cdot \frac{1}{\lambda(k)} \right| \times 100\% \]
平均级比偏差同样按上述标准评价。
(4)后验差检验
- 原始序列的方差 (S_1^2 = _{k=1}^{n} (x^{(0)}(k) - {x})^2)
- 残差序列的方差 (S_2^2 = _{k=1}^{n} (e(k) - {e})^2)
- 后验差比值 (C = S_2 / S_1)
- 小误差概率 (P = P{|e(k) - {e}| < 0.6745 S_1})
精度等级判定:
| 等级 | C | P |
|---|---|---|
| 好 | < 0.35 | > 0.95 |
| 合格 | < 0.50 | > 0.80 |
| 勉强合格 | < 0.65 | > 0.70 |
| 不合格 | ≥ 0.65 | ≤ 0.70 |
综合以上检验,给出模型适用性结论。
案例分析
案例背景:某企业 2015~2019 年的产品销售额(万元)如下,试预测 2020~2024 年的销售额。
| 年份 | 销售额 |
|---|---|
| 2015 | 2.5 |
| 2016 | 3.0 |
| 2017 | 3.6 |
| 2018 | 4.3 |
| 2019 | 5.2 |
取分辨系数 ()(固定),预测长度 (m=5)。
计算过程
1. 原始序列
\[ X^{(0)} = (2.5, 3.0, 3.6, 4.3, 5.2) \]
2. 级比检验
计算 ((2)=2.5/3.0=0.8333),((3)=3.0/3.6=0.8333),((4)=3.6/4.3=0.8372),((5)=4.3/5.2=0.8269)。
区间 (= (e^{-2/6}, e^{2/6}) = (0.7165, 1.3956)),所有级比均落在区间内,可直接建模。
3. 一次累加
\[ X^{(1)} = (2.5, 5.5, 9.1, 13.4, 18.6) \]
4. 构造 (B) 和 (Y)
背景值 (z^{(1)}(2)= (2.5+5.5)/2=4.0),(z{(1)}(3)=(5.5+9.1)/2=7.3),(z{(1)}(4)=(9.1+13.4)/2=11.25),(z^{(1)}(5)=(13.4+18.6)/2=16.0)。
\[ B = \begin{bmatrix} -4.0 & 1 \\ -7.3 & 1 \\ -11.25 & 1 \\ -16.0 & 1 \end{bmatrix}, \quad Y = \begin{bmatrix} 3.0 \\ 3.6 \\ 4.3 \\ 5.2 \end{bmatrix} \]
5. 求解参数
计算得: \[ \hat{a} = -0.1823, \quad \hat{b} = 2.482 \] (负的发展系数表示增长趋势)
6. 时间响应函数
\[ \hat{x}^{(1)}(k) = \left(2.5 - \frac{2.482}{-0.1823}\right) e^{0.1823(k-1)} + \frac{2.482}{-0.1823} = (2.5 + 13.62) e^{0.1823(k-1)} - 13.62 = 16.12 e^{0.1823(k-1)} - 13.62 \]
7. 拟合值与预测值
- 拟合值(累减还原):
- (k=1):2.5
- (k=2):16.12e^{0.1823} - 13.62 - 2.5 ≈ 3.01
- (k=3):≈ 3.62
- (k=4):≈ 4.35
- (k=5):≈ 5.23
- 预测值((k=6) 到 (10)):
- 2020: 6.29,2021: 7.57,2022: 9.11,2023: 10.96,2024: 13.19
8. 检验
- 平均相对误差:约 1.2%(良)
- 后验差比值 (C=0.12 < 0.35),小误差概率 (P=1>0.95) → 精度等级“好”
结论:模型精度高,预测结果可信。销售额将保持增长趋势,2024 年预计达到 13.19 万元。
常见问题
Q1: GM(1,1) 模型适用于哪些场景?
A: 适用于小样本(一般 4~10 个数据)、数据呈现指数增长或衰减趋势的短期预测。常见应用:经济指标预测、人口预测、粮食产量预测、电力负荷预测等。不适用于周期性波动大或随机性过强的序列。
Q2: 为什么要进行级比检验?
A: 级比检验用于判断原始序列是否适合建立 GM(1,1) 模型。若级比全部落在可容区间内,说明数据具有较好的光滑性和指数规律,模型精度较高;否则需对数据平移或考虑其他模型。
Q3: 发展系数 (a) 和灰色作用量 (b) 如何解读?
A: - (a < 0):序列呈增长趋势,(|a|) 越大增长越快;(a > 0):序列呈衰减趋势;(a) 接近 0 时序列接近常数。 - (b) 反映系统的“灰色作用量”,即外部因素对系统行为的影响程度,其绝对值越大表示外部驱动力越强。
Q4: 数据平移如何处理?
A: 当原始数据包含非正数或级比检验不通过时,系统会自动对所有数据加上一个常数 (c),使得新序列级比合格。预测完成后,预测值会自动减去 (c) 进行还原。用户可在结果中查看平移量。
Q5: 预测长度如何选择?
A: 一般建议预测长度不超过原始数据个数的 1/3(例如 6 个原始数据,预测不超过 2 步)。本平台允许自定义,但用户应结合模型精度判断:若后验差比值 C 较小(<0.35),可适当增加预测长度;否则应谨慎。
Q6: 支持多工作表吗?
A: 目前版本仅支持单工作表(单序列)分析。若需分析多个独立序列,可分别上传或多次运行。
平台功能
GM(1,1) 灰色预测平台提供以下核心功能:
数据输入
- 支持 CSV、Excel、TXT 多种格式。
- 数据格式要求:第一列为时间标识(年份、月份等),第二列为观测数据值。数据至少 4 行,从上到下时间递增。
参数设置
- 预测长度:未来预测的点数(默认 10)。
- 小数位数:控制结果精度(默认 4 位)。
- 显示中间计算过程:可选是否展示级比值、累加序列、矩阵 B 和 Y 等中间步骤。
- 绘图参数:可自定义图形标题、坐标轴标签、时间类型、颜色、线型、散点样式、字体、图形尺寸等。
结果展示
- 预测结果表:历史时间、观测值、拟合值,以及未来时间的预测值。
- 模型检验:级比检验、相对误差检验、级比偏差检验、后验差检验的结果表格及精度等级。
- 模型参数:发展系数 (a) 和灰色作用量 (b) 的值及含义说明。
- 精度等级说明:参考标准表格。
- 计算过程(可展开):级比值、累加序列、矩阵 B 和向量 Y(需勾选“显示中间计算过程”)。
- 可视化:历史数据、拟合值、预测值的折线图 + 散点图,支持丰富的绘图参数自定义,并可在历史/预测分界处绘制竖线。
- AI 智能分析:基于 DeepSeek API 自动解读模型精度和预测结果,提供决策建议(每日限 3 次)。
- 多格式导出:支持 Excel 和 HTML 报告下载。
使用建议
准备阶段:收集至少 4 个连续时间点的数据,确保数据非负且具有单调增长或衰减趋势。若数据波动大,可先进行平滑处理。
数据收集:使用平台提供的模板文件填写数据。第一列为时间(如年份),第二列为数值。确保无缺失值。
参数设置:
- 根据实际需求设置预测长度(一般不超过原始数据数量的 1/3)。
- 若想了解建模细节,勾选“显示中间计算过程”。
- 调整绘图参数以获得清晰直观的图形。
结果解读:
- 首先查看级比检验是否通过。若未通过但系统自动平移,应关注平移量是否合理。
- 检查平均相对误差和后验差比值 C 的精度等级。若精度等级为“不合格”,应谨慎使用预测结果。
- 发展系数 (a) 的符号和大小决定了趋势方向和速度,可据此判断未来走势。
- 利用 AI 分析获取专业解读和改进建议。
迭代优化:
- 若模型精度不理想,可尝试增加数据点、剔除异常值或对数据进行变换(如取对数)。
- 将预测结果与实际情况对比,检验模型的有效性。
- 可结合其他预测方法(如指数平滑、ARIMA)进行对比验证。
平台界面
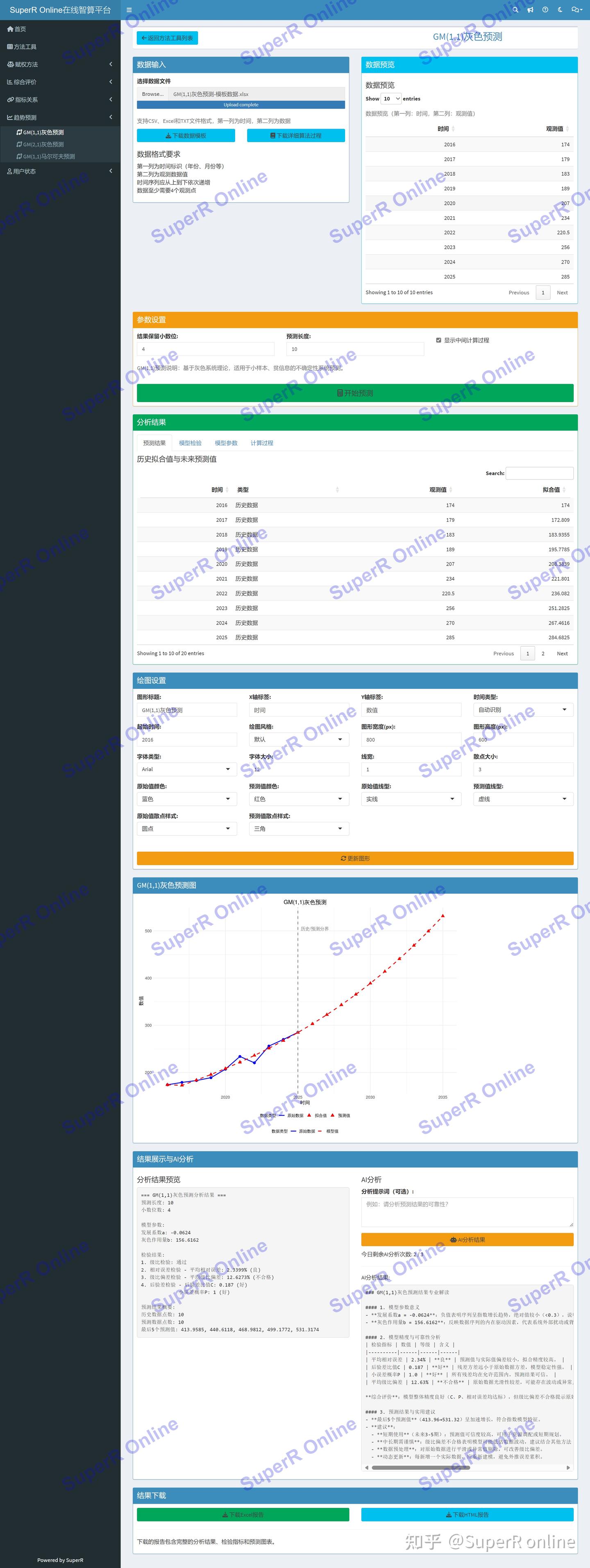灰色预测工具界面预览)
平台界面包含:数据上传区、参数设置区、数据预览、分析结果展示和AI分析模块
参考文献:
- 邓聚龙. 灰色系统理论教程[M]. 华中理工大学出版社,1990.
- 刘思峰,谢乃明. 灰色系统理论及其应用[M]. 科学出版社,2013.
- 基于 GM(1,1) 模型的经济预测研究[J]. 统计与决策,2008(22): 34-36.